- Linked allocation solves the external-fragmentation and size-declaration problems of contiguous allocation.
- However, in the absence of a FAT, linked allocation cannot support efficient direct access, since the pointers to the blocks are scattered with the blocks themselves all over the disk and must be retrieved in order.
- A data structure called an i-node (index-node), which lists the attributes and disk addresses of the files blocks (see Fig. 11.11).
Figure 11.11:
An example i-node.
|
|
- Indexed allocation solves this problem by bringing all the pointers together into one location: the index block.
- Each file has its own index block, which is an array of disk-block addresses.
- The
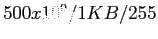 entry in the index block points to the block of the file. The directory contains the address of the index block (see Fig. 11.12).
entry in the index block points to the block of the file. The directory contains the address of the index block (see Fig. 11.12).
Figure 11.12:
Indexed allocation of disk space.
|
|
- To find and read the block, we use the pointer in the index-block entry. This scheme is similar to the paging scheme.
- Given the i-node, it is then possible to find all the blocks of the file. The big advantage of this scheme over linked files using an in-memory table is that the i-node need only be in memory when the corresponding file is open.
- When the file is created, all pointers in the index block are set to nil. When the block is first written, a block is obtained from the free-space manager, and its address is put in the index-block entry.
- When a file is opened, the file system must take the file name supplied and locate its disk blocks. Let us consider how the path name /usr/ast/mbox is looked up. The lookup process is illustrated in Fig. 11.13.
Figure 11.13:
The steps in looking up /usr/ast/mbox.
|
|
- Indexed allocation supports direct access, without suffering from external fragmentation, because any free block on the disk can satisfy a request for more space.
- Indexed allocation does suffer from wasted space, however. Consider a common case in which we have a file of only one or two blocks.
- With linked allocation, we lose the space of only one pointer per block.
- With indexed allocation, an entire index block must be allocated, even if only one or two pointers will be non-nil.
- This point raises the question of how large the index block should be.
- Every file must have an index block, so we want the index block to be as small as possible.
- If the index block is too small, however, it will not be able to hold enough pointers for a large file, and a mechanism will have to be available to deal with this issue.
- Mechanisms for this purpose include the followings.
- Linked scheme. An index block is normally one disk block. Thus, it can be read and written directly by itself. To allow for large files, we can link together several index blocks.
- For example, an index block might contain a small header giving the name of the file and a set of the first 100 disk-block addresses.
- The next address (the last word in the index block) is nil (for a small file) or is a pointer to another index block (for a large file).
- Multilevel index. A variant of the linked representation is to use a first-level index block to point to a set of second-level index blocks, which in turn point to the file blocks.
- To access a block, the OS uses the first-level index to find a second-level index block and then uses that block to find the desired data block.
- This approach could be continued to a third or fourth level, depending on the desired maximum file size.
- With 4096-byte blocks, we could store 1024 4-byte pointers in an index block.
- Two levels of indexes allow 1048576 data blocks and a file size of up to 4 GB.
Figure 11.14:
The UNIX inode.
|
|
- Combined scheme. Another alternative, used in the UFS (UNIX File System), is to keep the first, say, 15 pointers of the index block in the file's inode.
- The first 12 of these pointers point to direct blocks; that is, they contain addresses of blocks that contain data of the file.
- Thus, the data for small files (of no more than 12 blocks) do not need a separate index block.
- If the block size is 4 KB, then up to 48 KB of data can be accessed directly.
- The next three pointers point to indirect blocks.
- The first points to a single indirect block, which is an index block containing not data but the addresses of blocks that do
contain data.
- The second points to a double indirect block, which contains the address of a block that contains the addresses of blocks that contain pointers to the actual data blocks.
- The last pointer contains the address of a triple indirect block.
- Under this method, the number of blocks that can be allocated to a file exceeds the amount of space addressable by the 4-byte file pointers used by many OSs. A 32-bit file pointer:
 bytes, or 4 GB.
bytes, or 4 GB.
- Many UNIX implementations, including Solaris and IBM's AIX, now support up to 64-bit file pointers (terabytes).
- A UNIX inode is shown in Fig. 11.14.
- Indexed-allocation schemes suffer from some of the same performance problems as does linked allocation. Specifically, the index blocks can be cached in memory; but the data blocks may be spread all over a volume.
Summary of the allocation methods is given in Fig. 11.15.
Figure 11.15:
(a) Contiguous allocation (b) Contiguous allocation with compaction (c) Storing a file as a linked list of disk blocks (d) Storing a file as a linked list of disk blocks with defragmentation (e) Indexed allocation with block partitions (f) Indexed allocation with variable-length partitions.
|
Cem Ozdogan
2010-05-25
![\includegraphics[scale=0.6]{figures/11-14}](img392.png)
![\includegraphics[scale=0.45]{figures/11-09}](img393.png)
![\includegraphics[scale=0.8]{figures/11-15}](img394.png)
![\includegraphics[scale=0.5]{figures/11-10}](img395.png)
![\includegraphics[scale=0.45]{figures/11-16}](img396.png)
![\includegraphics[scale=0.45]{figures/11-17}](img397.png)
![\includegraphics[scale=0.45]{figures/11-18}](img398.png)
![\includegraphics[scale=0.45]{figures/11-19}](img399.png)
![\includegraphics[scale=0.45]{figures/11-20}](img400.png)
![\includegraphics[scale=0.45]{figures/11-21}](img401.png)