- For example, consider the following piece of code in which process 0 sends two messages with different tags to process 1, and process 1 receives them in the reverse order.
1 int a[10], b[10], myrank;
2 MPI_Status status;
3 ...
4 MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
5 if (myrank == 0) {
6 MPI_Send(a, 10, MPI_INT, 1, 1, MPI_COMM_WORLD);
7 MPI_Send(b, 10, MPI_INT, 1, 2, MPI_COMM_WORLD);
8 }
9 else if (myrank == 1) {
10 MPI_Recv(b, 10, MPI_INT, 0, 2, MPI_COMM_WORLD);
11 MPI_Recv(a, 10, MPI_INT, 0, 1, MPI_COMM_WORLD);
12 }
13 ...
- If MPI_Send is implemented using buffering, then this code will run correctly provided that sufficient buffer space is available.
- However, if MPI_Send is implemented by blocking until the matching receive has been issued, then neither of the two processes will be able to proceed. This code fragment is not safe, as its behavior is implementation dependent. It is up to the programmer to ensure that his or her program will run correctly on any MPI implementation.
- The problem in this program can be corrected by matching the order in which the send and receive operations are issued. Similar deadlock situations can also occur when a process sends a message to itself. Even though this is legal, its behavior is implementation dependent and must be avoided.
- Improper use of MPI_Send and MPI_Recv can also lead to deadlocks in situations when each processor needs to send and receive a message in a circular fashion.
- Consider the following piece of code, in which process
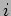 sends a message to process
sends a message to process 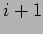 (modulo the number of processes) and receives a message from process
(modulo the number of processes) and receives a message from process 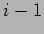 (module the number of processes).
(module the number of processes).
1 int a[10], b[10], npes, myrank;
2 MPI_Status status;
3 ...
4 MPI_Comm_size(MPI_COMM_WORLD, &npes);
5 MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
6 MPI_Send(a, 10, MPI_INT, (myrank+1)%npes, 1, MPI_COMM_WORLD);
7 MPI_Recv(b, 10, MPI_INT, (myrank-1+npes)%npes, 1, MPI_COMM_WORLD);
8 ...
- When MPI_Send is implemented using buffering, the program will work correctly, since every call to MPI_Send will get buffered, allowing the call of the MPI_Recv to be performed, which will transfer the required data.
- However, if MPI_Send blocks until the matching receive has been issued, all processes will enter an infinite wait state, waiting for the neighboring process to issue a MPI_Recv operation.
- Note that the deadlock still remains even when we have only two processes. Thus, when pairs of processes need to exchange data, the above method leads to an unsafe program. The above example can be made safe, by rewriting it as follows:
1 int a[10], b[10], npes, myrank;
2 MPI_Status status;
3 ...
4 MPI_Comm_size(MPI_COMM_WORLD, &npes);
5 MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
6 if (myrank%2 == 1) {
7 MPI_Send(a, 10, MPI_INT, (myrank+1)%npes, 1, MPI_COMM_WORLD);
8 MPI_Recv(b, 10, MPI_INT, (myrank-1+npes)%npes, 1, MPI_COMM_WORLD);
9 }
10 else {
11 MPI_Recv(b, 10, MPI_INT, (myrank-1+npes)%npes, 1, MPI_COMM_WORLD);
12 MPI_Send(a, 10, MPI_INT, (myrank+1)%npes, 1, MPI_COMM_WORLD);
13 }
14 ...
This new implementation partitions the processes into two groups. One consists of the odd-numbered processes and the other of the even-numbered processes.
![\includegraphics[scale=1]{figures/performances.ps}](img4.png)