- By far the simplest CPU-scheduling algorithm is the first-come, first-served (FCFS) scheduling algorithm. With this algorithm, processes are assigned the CPU in the order they request it.
- Basically, there is a single queue of ready processes. Relative importance of jobs measured only by arrival time (poor choice).
- The implementation of the FCFS policy is easily managed with a FIFO queue. When a process enters the ready queue, its PCB is linked onto the tail of the queue.
- The average waiting time under the FCFS policy, however, is often quite long. Consider the following set of processes that arrive at time 0, with the length of the CPU burst given in milliseconds:
| |
Burst |
Waiting |
Turnaround |
| Process |
Time |
Time |
Time |
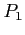 |
24 |
0 |
24 |
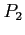 |
3 |
24 |
27 |
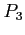 |
3 |
27 |
30 |
| Average |
- |
17 |
27 |
- If the processes arrive in the order
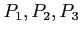 , and are served in FCFS order, we get the result shown in the following chart:
, and are served in FCFS order, we get the result shown in the following chart:
- If the processes arrive in the order
 , the results will be as shown in the following chart:
, the results will be as shown in the following chart:
- The average waiting time is now
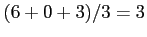 milliseconds.
milliseconds.
- This reduction is substantial. Thus, the average waiting time under an FCFS policy is generally not minimal and may vary substantially if the process's CPU burst times vary greatly.
- Assume we have one CPU-bound process and many I/O-bound processes. As the processes flow around the system (dynamic system), the following scenario may result.
- The CPU-bound process will get and hold the CPU. During this time, all the other processes will finish their I/0 and will move into the ready queue, waiting for the CPU.
- While the processes wait in the ready queue, the I/O devices are idle. Eventually, the CPU-bound process finishes its CPU burst
and moves to an I/0 device.
- All the I/O-bound processes, which have short CPU bursts, execute quickly and move back to the I/0 queues.
- At this point, the CPU sits idle. The CPU-bound process will then move back to the ready queue and be allocated the CPU.
- Again, all the I/O processes end up waiting in the ready queue until the CPU-bound process is done.
- There is a convoy effect as all the other processes wait for the one big process to get off the CPU. A long CPU-bound job may take the CPU and may force shorter (or I/O-bound) jobs to wait prolonged periods.
- This effect results in lower CPU and device utilization than might be possible if the shorter processes were allowed to go first.
- Another Example: Suppose that there is one CPU-bound process that runs for 1 sec at a time and many I/O-bound processes that use little CPU time but each have to perform 1000 disk reads to complete.
- The CPU-bound process runs for 1 sec, then it reads a disk block.
- All the I/O processes now run and start disk reads.
- When the CPU-bound process gets its disk block, it runs for another 1 sec, followed by all the I/O-bound processes in quick succession.
- The net result is that each I/O-bound process gets to read 1 block per second and will take 1000 sec to finish.
- With a scheduling algorithm that preempted the CPU-bound process every 10 msec, the I/O-bound processes would finish in 10 sec instead of 1000 sec, and without slowing down the CPU-bound process very much.
- The FCFS scheduling algorithm is nonpreemptive. Once the CPU has been allocated to a process, that process keeps the CPU until it releases the CPU, either by terminating or by requesting I/0.
Figure 1:
An example to First-Come First-Served.
|
|
Cem Ozdogan
2010-03-23
![\includegraphics[scale=1]{figures/05-01}](img6.png)
![\includegraphics[scale=1]{figures/05-02}](img8.png)
![\includegraphics[scale=0.8]{figures/05-12}](img10.png)